Best Vector Databases for AI (2026)




Best Vector Databases for AI in 2026
If you're researching the best vector databases for AI in 2026, the category has matured into a clear set of category leaders across managed cloud, open-source self-hosted, multimodal search, and hybrid search use cases. The 2024–2026 wave of generative AI applications made vector storage and similarity search a foundational primitive — every RAG pipeline, every semantic-search system, every recommendation engine, and every AI agent with long-term memory needs vector storage underneath.
This guide covers the eight vector databases real engineering teams use in 2026: Pinecone, Weaviate, Chroma, Qdrant, Milvus, Marqo, Vespa.ai, and Zilliz. Each is rated on which use case it owns, the production credibility behind the pitch, and which type of team it fits.
How We Evaluated These Tools
The eight vector databases below were evaluated on five criteria, in priority order:
- Real production deployments at AI-led organizations — verified usage at companies running RAG, semantic search, or AI-agent memory at scale
- Performance benchmarks — independent latency and recall benchmarks (ANN-Benchmarks, vendor disclosures, third-party reviews)
- Hybrid search support — combined dense + sparse + metadata filtering, the 2026 baseline expectation for production RAG
- Pricing and access — managed cloud + self-hosted open-source variants where applicable, transparent pricing
- 2026 currency — has the database shipped meaningful capability in the last 12 months (LLM-era features like hybrid search, agentic-memory primitives, multimodal indexing)
We deliberately did not include general-purpose databases that bolted on vector indexing (Postgres + pgvector, Elasticsearch + dense_vector, MongoDB Atlas Vector Search) — those have their place in mixed workloads but the vector-DB-native tools below are what dedicated AI workloads run on. For the broader AI infrastructure layer, see Best AI Infrastructure & MLOps Tools (2026).
The Four Lanes of 2026 Vector Databases
- Managed cloud: Pinecone (the canonical commercial leader), Zilliz (managed Milvus).
- Open-source self-hosted leaders: Weaviate, Qdrant, Milvus, Chroma.
- Multimodal vector search: Marqo (purpose-built for multimodal indexing).
- Search engine + vector hybrid: Vespa.ai (Yahoo-grown, hybrid keyword + vector + ML ranking).
Most mature 2026 RAG and AI-application teams pick by the deployment constraint — managed cloud for ship-fast applications, open-source self-hosted for cost-sensitive scale or strict data residency, specialty tools (Marqo, Vespa) for the use cases the leaders don't fit.
Quick Comparison
| Tool | Best for |
|---|---|
| Pinecone | Managed cloud vector database. Best for ship-fast production RAG without infrastructure ownership. |
| Weaviate | Open-source vector database with strong hybrid search. Best for self-hosted RAG with hybrid-search needs. |
| Chroma | Open-source embedding database. Best for AI prototyping and small-scale production. |
| Qdrant | Open-source vector database in Rust. Best for performance-sensitive self-hosted deployments. |
| Milvus | Open-source vector database for large-scale workloads. Best for billion-scale vectors. |
| Marqo | Multimodal vector search platform. Best for image + text combined search. |
| Vespa.ai | Search engine + vector hybrid. Best for combined keyword + vector + ML-ranked search. |
| Zilliz | Managed Milvus cloud. Best for Milvus users who want managed deployment. |
Managed Cloud
1. Pinecone — The Managed-Cloud Leader
Pinecone is the most-deployed managed vector database in 2026 — the default ship-fast choice for production RAG, semantic search, and AI agent memory. The 2024 serverless launch made the pricing model substantially friendlier for variable-load workloads; the 2025 hybrid-search and metadata-filtering features matched the open-source leaders' capabilities at the managed tier.
Production credibility: raised $138M+ Series B at a $750M valuation (2023) led by Andreessen Horowitz; deployed at Notion, Microsoft, Shopify, Brex, Gong, and many AI-led companies; serverless tier launched in 2024 became the canonical reference for variable-load vector workloads.
What it wins at: ship-fast production RAG without infrastructure ownership, the serverless pricing model that scales with usage, and the procurement-friendly enterprise tier with SOC 2 Type II + GDPR compliance.
Where it falls down: for cost-sensitive at-scale workloads (>1B vectors with sustained high QPS), self-hosted open-source becomes more economical. For data-residency-strict deployments, the open-source self-hosted alternatives are the cleaner option.
Open-Source Self-Hosted
2. Weaviate — Open-Source with Strong Hybrid Search
Weaviate is the open-source vector database with the most mature hybrid-search story (combined dense + BM25 sparse + metadata filtering in a single query). For self-hosted RAG deployments where hybrid search matters more than pure ANN performance, Weaviate is the canonical pick.
Production credibility: raised $50M+ Series B at a $200M+ valuation (2024); the open-source project has tens of thousands of GitHub stars and a large community; managed cloud variant available; deployed across enterprise self-hosted RAG workloads.
What it wins at: self-hosted RAG with hybrid-search needs, the GraphQL-based query interface for developers who prefer it over REST/Python clients, and the strong ecosystem of integrations (LangChain, LlamaIndex, Spring AI).
Where it falls down: for pure raw-throughput at billion-scale, Milvus and Qdrant typically benchmark faster. Weaviate's strengths are query expressiveness and hybrid search rather than peak-throughput indexing.
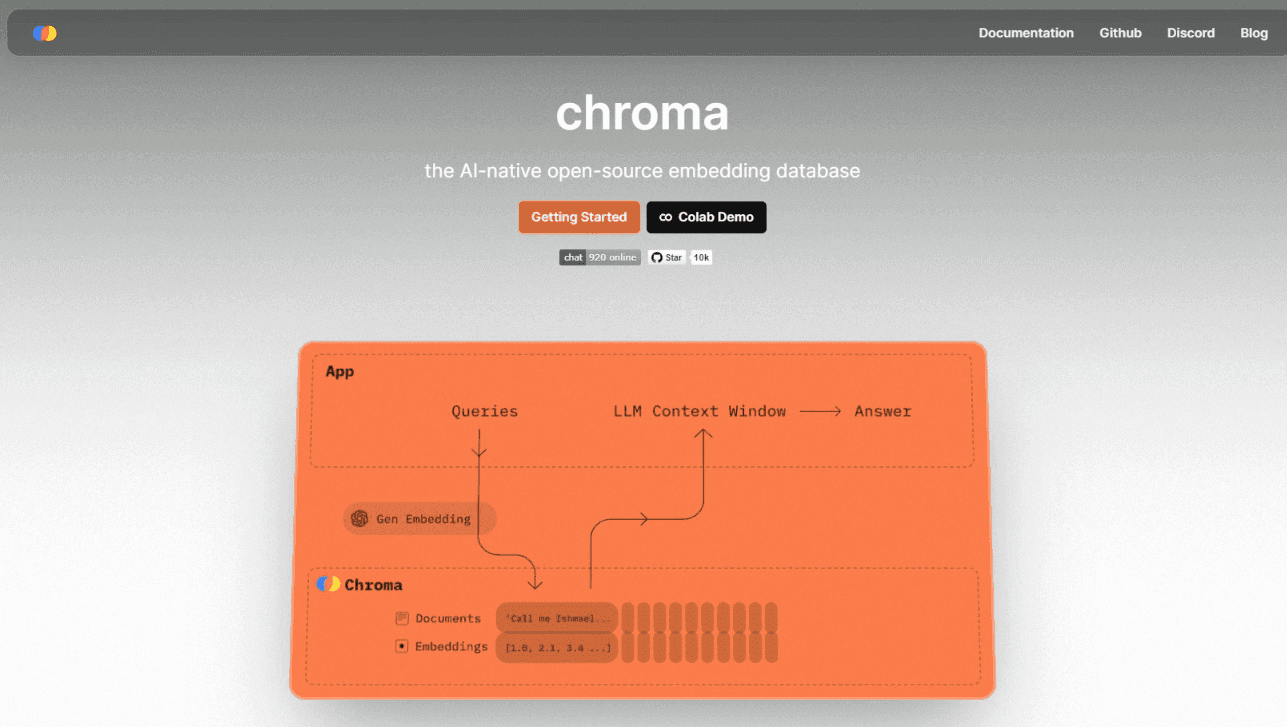
3. Chroma — The Embedding Database for AI Prototyping
Chroma is the open-source embedding database designed specifically for AI application prototyping and small-to-medium production workloads. The Python-first developer experience (pip install chromadb, embed → store → query in five lines of code) made it the canonical RAG-prototyping tool through the 2023–2025 LLM-application wave.
Production credibility: raised $20M+ across rounds led by Quiet Capital, AIX Ventures, and Naval Ravikant; deployed widely across AI-application teams using LangChain and LlamaIndex; consistently the most-cited vector store in independent surveys of LLM-application developers.
What it wins at: AI application prototyping, small-to-medium production workloads (under ~10M vectors), and the use case where developer experience and quick-start friction matter more than scale-out performance.
Where it falls down: for large-scale production workloads (hundreds of millions of vectors, sustained high QPS), Pinecone, Weaviate, or Milvus all scale better. Chroma is the prototype-and-small-scale tool specifically.
4. Qdrant — Performance-Focused Open-Source
Qdrant is the open-source vector database written in Rust, with consistent benchmark wins on raw ANN performance and resource efficiency. For performance-sensitive self-hosted deployments where the cost-per-query matters, Qdrant is the canonical pick.
Production credibility: raised $28M+ Series A at a $250M+ valuation (2024); the open-source project has tens of thousands of GitHub stars; managed cloud variant available; deployed across performance-critical AI applications.
What it wins at: performance-sensitive deployments, resource-efficient self-hosting at scale, and the Rust-based stack for engineers who value memory safety and predictable performance characteristics.
Where it falls down: ecosystem and integration depth trail Weaviate and Pinecone. For teams that need broad LangChain/LlamaIndex/framework support, the larger ecosystems fit better — though Qdrant's integration coverage is improving rapidly.
5. Milvus — Open-Source for Billion-Scale Workloads
Milvus is the open-source vector database designed for billion-scale vector workloads — the architecture is built around horizontal scaling for the largest production AI deployments. For teams running search across hundreds of millions or billions of vectors, Milvus is the canonical choice.
Production credibility: Linux Foundation graduated project under LF AI; backed by Zilliz (which provides the managed cloud variant); deployed at IKEA, Walmart, NVIDIA, Tencent, and other large-scale production AI workloads; >30K GitHub stars across the Milvus and PyMilvus repos.
What it wins at: billion-scale vector workloads, horizontal-scale architecture for the largest production deployments, and the open-source-with-commercial-managed-option (via Zilliz) for teams that want both options.
Where it falls down: for small-to-medium workloads, the operational complexity is overkill — Chroma or Qdrant ship faster. Milvus is the right choice when scale forces it.
Multimodal and Hybrid
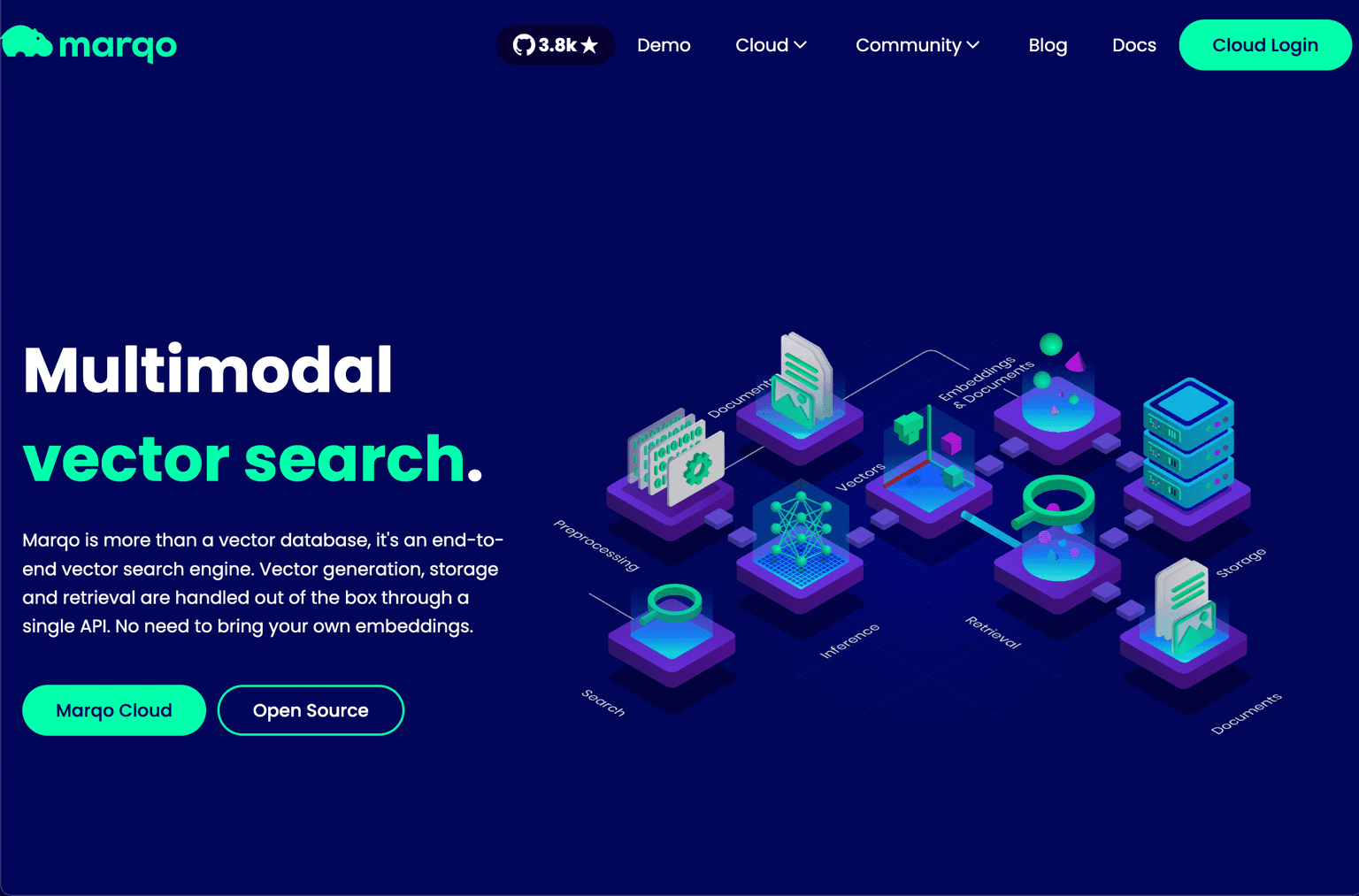
6. Marqo — Multimodal Vector Search
Marqo is the vector-search platform purpose-built for multimodal indexing — search across images and text in a single index without separate pre-processing pipelines. For e-commerce product search, content-discovery applications, and any workflow where image + text semantic similarity matters, Marqo's multimodal-first design is the differentiator.
Production credibility: raised $5.2M+ seed in 2022 led by Square Peg Capital; reported deployments at e-commerce and content-discovery use cases; the multimodal-first architecture is the meaningful differentiator in a sea of dense-vector-only databases.
What it wins at: multimodal search (image + text combined), e-commerce product search workflows, and the use case where building separate text and image indexes is the wrong abstraction.
Where it falls down: for pure text-RAG workloads, the multimodal capability is wasted. Marqo is the multimodal-search specialist; pure-text alternatives are simpler and cheaper.
7. Vespa.ai — Search Engine + Vector Hybrid
Vespa.ai is the search engine + vector hybrid platform spun out of Yahoo's internal infrastructure — combines traditional inverted-index keyword search, dense vector search, and ML-driven ranking in a single platform. For teams running search across structured + keyword + vector + ranking-model workflows, Vespa is the most mature option.
Production credibility: open-source under Apache 2.0 license; deployed at Yahoo, Spotify, and several large-scale search workloads; the hybrid-search architecture is more mature than the vector-DB-native alternatives because Vespa started as a search engine and added vectors rather than the other way around.
What it wins at: combined keyword + vector + ML ranking, large-scale search workloads where the combined ranking matters more than pure vector similarity, and the search-engine-first architecture that vector-DB-native tools approximate but don't fully match.
Where it falls down: operational complexity is high — Vespa is sized for search infrastructure teams, not for AI application developers prototyping RAG. For pure RAG, Pinecone or Chroma ship far faster.
Managed Open-Source
8. Zilliz — Managed Milvus Cloud
Zilliz is the company behind Milvus and the provider of Zilliz Cloud — managed Milvus deployment without the operational overhead of self-hosting. For teams that want Milvus's billion-scale capability with managed-cloud convenience, Zilliz is the canonical pick.
Production credibility: raised $113M+ Series B at a $400M+ valuation (2022); funded by Hillhouse Capital, Temasek, Pavilion Capital, and others; the Zilliz Cloud managed service is the commercial path for Milvus users who don't want to operate the infrastructure themselves.
What it wins at: Milvus users who want managed-cloud deployment, billion-scale workloads with managed operations, and the Milvus ecosystem advantages (Apache 2.0 open source + commercial managed) without the self-hosting complexity.
Where it falls down: for non-Milvus teams, Pinecone fits better — Zilliz's value prop is specifically for Milvus users. The managed pricing competes with Pinecone's serverless tier; evaluate both for the specific workload before committing.
How to Pick a Vector Database in 2026
Match the database to the workload:
- AI prototyping and quick-start applications: Chroma (Python-first, low friction).
- Production RAG, ship-fast managed cloud: Pinecone serverless.
- Self-hosted RAG with hybrid search needs: Weaviate.
- Performance-sensitive self-hosted deployments: Qdrant.
- Billion-scale vector workloads: Milvus (open-source self-hosted) or Zilliz (managed cloud).
- Multimodal search (image + text): Marqo.
- Combined keyword + vector + ML-ranked search: Vespa.ai.
- Mixed-workload database with vector capability: Postgres + pgvector or MongoDB Atlas Vector (not in this list — see general-purpose database guides).
The most-recommended 2026 starting investment for an AI application team without a vector database: Chroma for prototyping, then Pinecone serverless when you ship to production. Switch to self-hosted (Weaviate, Qdrant, Milvus) when scale or cost forces it, typically above 50M vectors or sustained high QPS.
Adjacent Reading
- Best AI Infrastructure & MLOps Tools (2026) — broader ML infrastructure stack
- Best AI Development Frameworks (2026) — LangChain, LlamaIndex, the application layer
- Best LLMs (2026) — foundation models powering RAG
- Top 7 AI Coding Assistants for Engineering Teams — developer tooling
- Best AI Tools for Data Visualization & Analytics — analytics adjacent
Frequently Asked Questions
What's the best vector database for AI in 2026? Depends on the workload. For ship-fast production RAG: Pinecone serverless. For self-hosted with hybrid search: Weaviate. For performance-sensitive self-hosted: Qdrant. For billion-scale: Milvus (or Zilliz Cloud for managed). For prototyping: Chroma. For multimodal search: Marqo. For combined keyword+vector+ranking: Vespa. There isn't one tool that wins all use cases.
Do I need a dedicated vector database, or will Postgres + pgvector work? For mixed-workload applications (the database is doing more than vector search), Postgres + pgvector or MongoDB Atlas Vector Search is often sufficient and operationally simpler. For dedicated vector workloads at scale or where pure vector search performance matters, the dedicated databases above outperform meaningfully — typically 5–10× lower latency at the same recall.
What's the difference between dense vector search and hybrid search? Dense vector search uses learned embeddings (text → 768-1536 dim vector → similarity). Hybrid search combines dense vectors with sparse keyword search (BM25) and metadata filters in a single query. For most production RAG, hybrid search produces meaningfully better results than dense-only. Weaviate, Vespa, and Pinecone all support hybrid search natively.
Are these vector databases safe for sensitive data? The enterprise tiers of Pinecone, Weaviate Cloud, Zilliz Cloud, and Qdrant Cloud all carry SOC 2 Type II compliance. Self-hosted open-source variants give the strictest privacy posture (your data never leaves your infrastructure). For regulated workloads (healthcare, financial services, defense), use the enterprise managed tier with appropriate compliance certifications, or self-host.
What's the typical cost for a 2026 vector database? Prototyping (Chroma local + Pinecone free tier): $0–$50/month. Small production (1–10M vectors): $50–$500/month. Mid-market (10–100M vectors): $500–$5,000/month. Large-scale (>100M vectors): $5,000+/month, with self-hosted options often more economical above this scale. The compute and storage costs typically dominate over the vector database licensing — pure infrastructure is the larger spend.
Should I use one vector database or multiple? Most AI applications use one vector database. The exception: teams with dramatically different workloads (high-QPS production RAG + cost-sensitive analytical workloads) sometimes use Pinecone for the production tier and Milvus / Qdrant self-hosted for batch analytics. Most teams find one database sufficient.
Will general-purpose LLMs eliminate the need for vector databases? No. Long-context LLMs (Gemini 1M+ tokens) reduce some short-context RAG use cases, but for any application where the source data is larger than the context window or the data is updated frequently, vector databases remain the canonical retrieval primitive. The category continues to grow alongside the LLM context-window expansion, not in opposition to it.
Final Thoughts
The vector database category in 2026 has consolidated around a clear set of category leaders by use case — Pinecone for managed cloud, Weaviate for hybrid-search self-hosted, Chroma for prototyping, Qdrant for performance, Milvus and Zilliz for scale, Marqo for multimodal, Vespa for combined search-and-vector workloads.
For any AI application team without a vector database in production, the highest-ROI 2026 move is: start with Chroma for prototyping, ship Pinecone serverless to production, switch to self-hosted (Weaviate, Qdrant, Milvus) when scale or cost forces it. The seat costs are typically <10% of total AI infrastructure spend; the time spent picking the wrong database early compounds into a multi-quarter migration cost.
Categories these tools span
More collections you may also like


Sign up for our newsletter
Receive weekly updates so you can stay up-to-date with the world of AI
Sign up for our newsletter
Receive weekly updates so you can stay up-to-date with the world of AI
The AI tools directory for discovering, exploring, and comparing the most innovative AI tools in the industry