Physical Intelligence
First foundation model for general robot control — Pi-zero (π0) is a vision-language-action flow model from a team including Sergey Levine. Open source.
Overview
Physical Intelligence: Pi-Zero (π0) Foundation Model
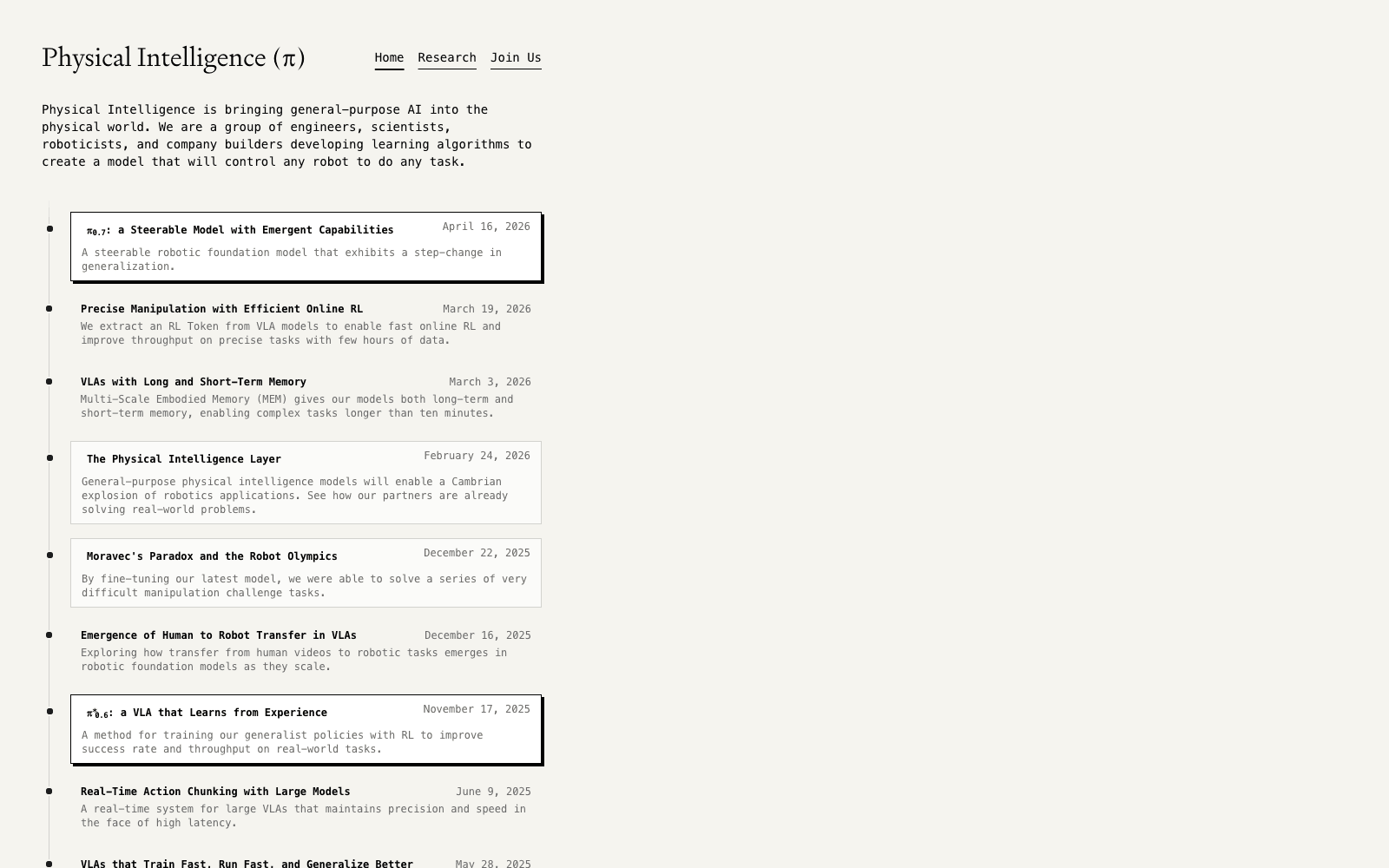
Physical Intelligence (Pi) is the AI lab building foundation models for general robot control — co-founded by Sergey Levine (UC Berkeley) and a team of researchers from Google, OpenAI, and Stanford. Their flagship model, π0 (pi-zero), is the first foundation model demonstrably capable of controlling many different robots performing many different real-world tasks (laundry folding, table bussing, manipulation) without per-task fine-tuning.
Open-sourced in 2025, π0's vision-language-action (VLA) flow architecture has become a reference design that other robotics labs are building on. The lab is racing alongside Skild AI to define the foundation-model approach to robotics.
Key Features
- π0 — first foundation model for general robot control
- Vision-language-action (VLA) flow architecture
- Demonstrated on real-world unscripted tasks (laundry folding, etc.)
- Open-sourced in 2025
- Co-founded by Sergey Levine, leading RL researcher
Ideal Use Case
Robotics labs and engineering teams adopting foundation-model approaches, ML researchers studying VLA architectures, and any organization deploying robots that wants to leverage the open-sourced π0 weights as a starting point.
Why Use Physical Intelligence
While Skild AI is the well-funded commercial leader, Physical Intelligence's open-source release of π0 has made the lab the academic and developer-mindshare leader. For research and tinkering, Pi is the more open path; for commercial deployment, Skild may have the edge.
FAQ
Q: Is π0 actually open source? A: Yes — model weights and inference code released in 2025 under permissive license.
Q: How does Physical Intelligence compare to Skild AI? A: Both target general-purpose robot foundation models. Pi has stronger open-research positioning; Skild has stronger commercial/customer traction.
Q: What does VLA mean? A: Vision-Language-Action — a model architecture that takes vision + language input and produces action sequences. The dominant pattern for robot foundation models.
tl;dr
Open-source robot foundation model. π0 is the first general-purpose robot brain. Co-founded by Sergey Levine. The OSS path to robotics foundation models.
Related
Looking for more options? Browse the AI Infrastructure directory or read our best AI infrastructure tools listicle. Physical Intelligence is also tracked on Crunchbase.
Why Use Physical Intelligence
User Reviews
Similar Tools