OctoML
OctoML offers world-class compute infrastructure for tuning and running models efficiently.
Acquired OctoML
Acquired · September 2024
Acquired by NVIDIA on 2024-09-25 for ~$250M. Originally OctoML, rebranded to OctoAI before acquisition. Wound down commercial services 2024-10-31.
Acquired by NVIDIA.
Is OctoML shut down?
No — OctoML is still operating, but it no longer stands alone: it was acquired by NVIDIA in Sep 2024 and continues under the acquirer's ownership. We list it in the ToolDirectory.AI graveyard's acquired-but-operating section and watch for post-acquisition changes.
What to use instead
Grok
Elon Musk's xAI aims to understand the universe's true nature.
Paid - Inquire
4.92
483

fal.ai
Fastest generative AI platform for developers — 1,000+ image, video, audio, and 3D models with optimized real-time inference. Default home for FLUX, SAM, MuseTalk.
Freemium
4.93
491

Vercel AI SDK
Universal TypeScript SDK from Vercel for building AI apps and agents with multi-model support.
Free
4.93
480
Overview
OctoML: Pioneering Efficient Model Tuning and Execution
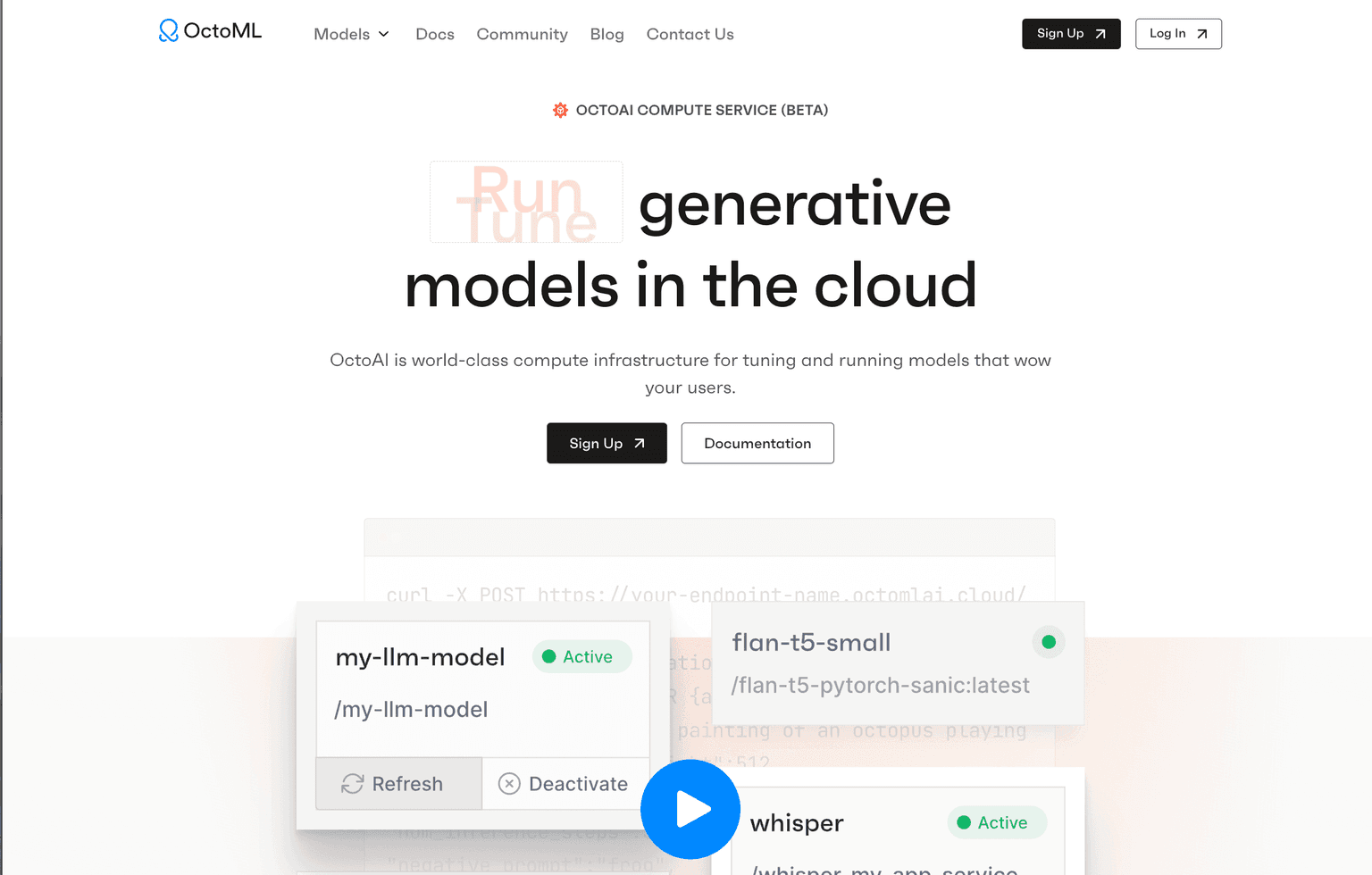
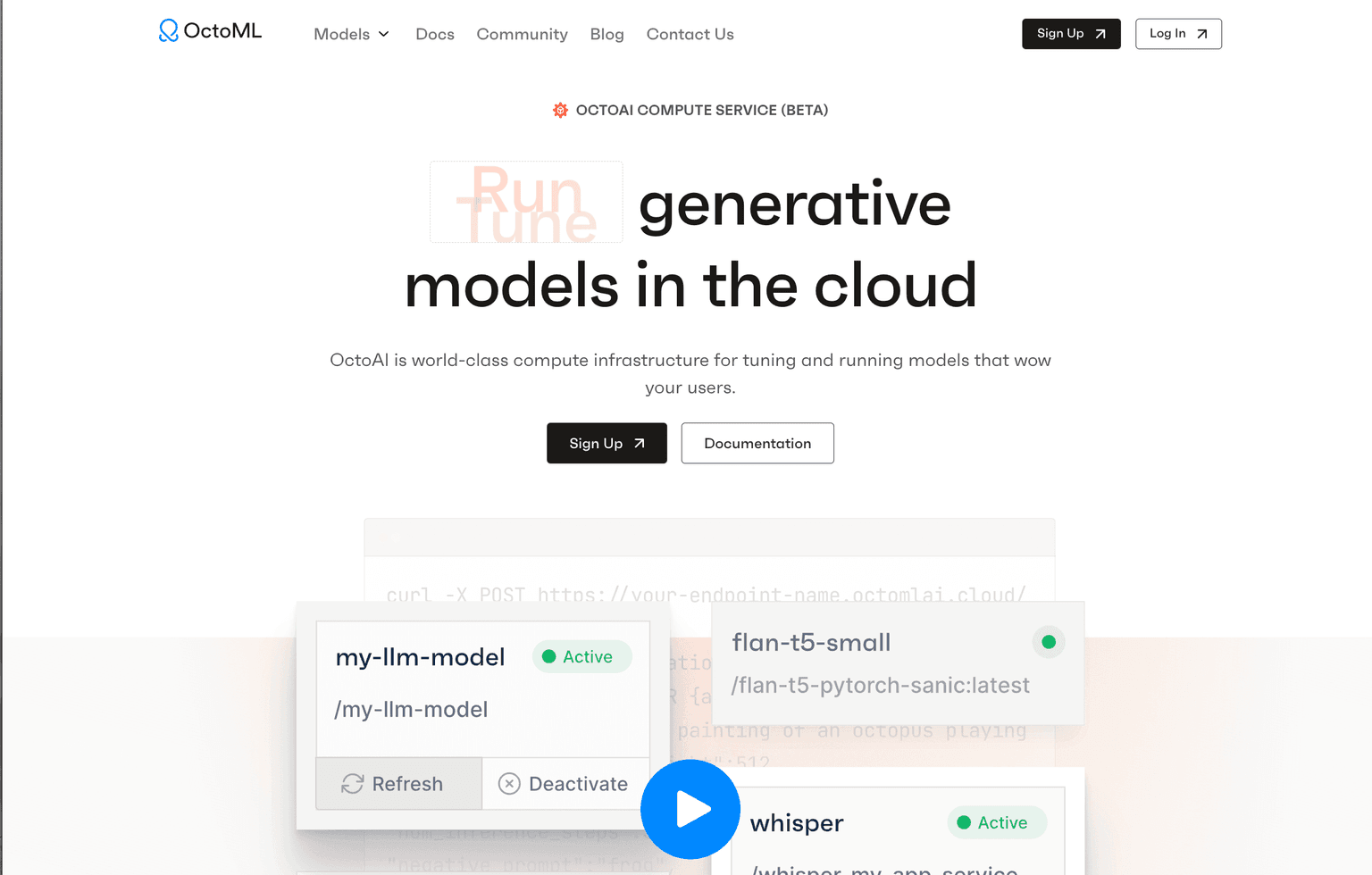
OctoML stands out as a groundbreaking compute service designed to optimize the tuning and execution of generative models in the cloud. This platform is engineered to empower developers, ensuring that models are not only efficient but also deliver exceptional performance to end-users.
Key Features:
- Develop with Any Model: OctoML boasts a flexible framework that supports both its accelerated models and custom models from external sources.
- Run with Ease: Developers can effortlessly set up ergonomic model endpoints within minutes, requiring minimal code.
- Fine-tune Freely: The platform offers customization options, allowing users to adapt models to specific use cases.
- Scale Efficiently: OctoML ensures scalability, accommodating user growth without compromising on hardware efficiency, speed, or cost.
Ideal Use Case:
OctoML is perfect for developers and businesses that require efficient model tuning and execution without the overhead of managing infrastructure. Whether you're a startup looking to deploy your first model or an enterprise aiming to scale your AI operations, OctoML provides the tools and infrastructure to make it happen seamlessly.
Why use OctoML:
- Optimized Models: Access to a curated list of top-tier open-source foundation models, optimized for both speed and cost.
- Self-Optimizing Compute: OctoML's compute service programmatically optimizes models using cutting-edge acceleration and compilation techniques.
- Expertise: The team behind OctoML includes leaders in ML systems and compilation, ensuring that the models are of the highest quality and efficiency.
- Flexibility: The platform supports a wide range of models, from those optimized by OctoML to custom models developed externally.
tl;dr:
OctoML provides a robust compute service tailored for the efficient tuning and execution of generative models in the cloud. With a focus on flexibility, scalability, and performance, it offers developers a streamlined platform to deploy and manage their models with ease.
FAQ
Q: What is OctoML used for? A: OctoML offers world-class compute infrastructure for tuning and running models efficiently.
Q: How is OctoML priced? A: Pricing varies by plan. Visit the OctoML pricing page for current tiers and details.
Q: Who benefits from OctoML? A: OctoML is designed for ML engineers and platform teams.
Q: What are alternatives to OctoML? A: Top alternatives to OctoML include Grok, fal.ai, and Vercel AI SDK. Browse the directory for full feature comparisons across these tools.
Related
Looking for more options? Browse the AI Infrastructure directory or read our best AI infrastructure tools listicle. OctoML is also tracked on Crunchbase.
Why Use OctoML